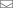Ходить как человек: генеративный ИИ и локомоция

Глядя на улицы города утром буднего дня, мы видим множество людей, каждый из которых торопливо или размеренно идет куда-то по своим делам, будь то на учебу или на работу. Скорость, особенности шага и общая картина локомоции человеческой ходьбы являются уникальными для каждого человека. При этом обстоятельства окружающей среды имеют немалое влияние на то как ходит человек. Говоря о роботах, мы уже давно научили их ходить, подобно человеку. Однако адаптация к динамическим условиям окружающей среды, особенно настройка скорости в реальном времени, остаются крайне сложной задачей. Ученые из Университета Тохоку (Япония) разработали новую методику обучения роботов, использовав возможности генеративного ИИ. Насколько данная методика была эффективной для обучения роботов, и насколько лучше стала их локомоция? Ответы на эти вопросы мы найдем в докладе ученых.
Основа исследования
Антропоморфные роботы являются центром внимания не только писателей-фантастов, но и научных сообществ во всем мире. На данный момент существует множество исследований и разработок из области робототехники, основная задача которых заключается в наделении роботов особенностями, присущим человеку (поведение, внешний вид, манера общения, локомоция и т. д.).
Когда-то роботы были неуклюжи и не могли даже близко сравниться в локомоции с человеком. Даже методы передвижения были иными (колеса, гусеницы и т. д.). Благодаря огромному труду инженеров роботы обзавелись двуногим передвижением, которое не только открыло новое окно возможностей, но и породило множество новых вопросов.
Одной из самых явных проблем двуногого передвижения роботов является адаптация под динамические условия окружающей среды. Некоторые существующие роботы-гуманоиды, в том числе продвинутые модели, такие как Atlas от Boston Dynamics, добились значительного прогресса. Но даже они еще не обладают стопроцентной адаптируемостью. Ученые считают, что усовершенствовать роботов можно с помощью новых методов их обучения.
За последние годы особое внимание приобрел алгоритм машинного обучения, называемый «глубокое обучение с подкреплением» (DRL от deep reinforcement learning). DRL предполагает обучение агента освоению оптимального поведения посредством взаимодействия с окружающей средой методом проб и ошибок, используя сигнал вознаграждения для управления своими действиями. В робототехнике DRL используется для улучшения выполнения различных задач, таких как захват объектов и передвижение, особенно у четвероногих роботов. Однако одним из текущих препятствий в применении DRL к роботам-гуманоидам является большое пространство, которое необходимо исследовать, и дисбаланс двуногого передвижения. Это затрудняет непосредственное обучение желаемой походке, поскольку существует множество возможных комбинаций движений, которые следует учитывать, и многие из них приводят к падениям. Проще говоря, DRL метод обучения может работать эффективно, если учесть все возможные комбинации условий окружающей среды, а также учесть изменчивость этих условий в реальном времени.
Когда речь заходит о каком-либо обучении искусственных систем, ученые часто обращаются за вдохновением к биологическим системам. К примеру, центральный генератор упорядоченной активности (CPG от central pattern generator) является результатом этого вдохновения. CPG — это нейронные цепи, расположенные в спинном мозге, которые генерируют ритмические паттерны мышечной активности, например те, которые используются во время ходьбы и бега. Используя CPG, роботы могут достигать более естественных и стабильных движений, аналогичных движениям живых организмов. Механизм CPG включает сеть взаимосвязанных нейронов, генерирующих колебательные сигналы, которые передаются мышцам, ответственным за движение.
У животных рефлекторная цепь обычно работает вместе с CPG в качестве контроля по принципу обратной связи. Вычислительные модели использовались для исследования слияния CPG с сенсорной обратной связью. Однако вопрос о том, как эффективно интегрировать и применять их для управления передвижением двуногих роботов, остается нерешенным, поскольку CPG потенциально могут ограничить пространство управления и помочь уменьшить размерность, но чтобы быть адаптивными и гибкими для различных сред, они должны хорошо поддерживаться рефлекторными сетями.
Авторы рассматриваемого нами сегодня труда заявляют, что их исследование направлено на улучшение алгоритмов обучения для передвижения роботов с использованием CPG и механизма сенсорной обратной связи. Ученые обучили контроллер CPG, используя имитационное обучение, а затем обучили рефлекторную нейронную сеть, используя DRL. В отличие от других алгоритмов, которые используют обучение с подкреплением для целей имитации, цель рассматриваемого обучения заключалась не только в том, чтобы заставить агента вести себя аналогично собранным данным о движениях человека. Вместо этого использовалось имитационное обучение, чтобы обучить CPG-подобный контроллер формированию управления с прямой связью.
CPG-подобный контроллер был разработан для генерации ритмических паттернов вращающих моментов суставов, аналогичных тем, которые генерируются CPG в живых организмах. Ученые использовали имитационное обучение для формирования шаблонов обучения CPG, чтобы избежать сложных вычислений и настройки, необходимых для других нелинейных функций. Затем рефлекторную нейронную сеть обучили с помощью DRL, чтобы корректировать движения, генерируемые CPG-подобной сетью, на основе сенсорной обратной связи, что позволяет роботу адаптироваться к изменениям в окружающей среде. Важно отметить, что в этом исследовании обучение с подкреплением используется для формирования рефлекторной нейронной сети для поддержки CPG, а не для формирования самого CPG.
Методология обучения

Изображение №1
Система управления — адаптивная имитируемая CPG (AI-CPG от adaptive imitated CPG) — состоит из следующих элементов (1b):
- генератор ритма (G), определяющий ритм двигательной активности;
- слой (S) формирования шаблона, который формирует ритмические сигналы синхронизации в соответствии с целевыми углами суставов робота;
- PD контроллер, который выводит моторные команды на основе ошибки между текущими углами суставов и целевыми углами суставов;
- контроллер рефлекторной нейронной сети ® на основе сенсорной обратной связи.
В процессе управления движением робота команда скорости на 1b модулирует скорость робота, изменяя частоту G и S. Это соответствует аналогичному механизму на 1a, где мозг регулирует двигательный паттерн человека путем нисходящей модуляции в спинномозговую сеть. Предыдущие исследования показали, как нисходящая модуляция регулирует активность CPG, взаимодействует с сенсорно-управляемой моделью и облегчает переходы от ходьбы к бегу. G и S служат контроллерами CPG с прямой связью, которые уменьшают размерность пространства действий робота, используя предварительные знания. Напротив, R служит контроллером обратной связи, отвечающим за поддержание баланса робота и адаптацию к данной физической среде.

Изображение №2
Как показано на 2a и 2b, ученые обучали S посредством имитационного обучения, используя данные о движениях человека из CMU базы данных захвата движений, которая состояла из набора данных о походке как для ходьбы, так и для бега. Ученые использовали быстрое преобразование Фурье (FFT от fast Fourier transform) для получения частот движения fw и fr для двух наборов данных. На основе частот движения и G были рассчитаны входные функции, используемые для обучения. После сопоставления входных функций с реальными данными о движении во временном ряду были получены наборы обучающих данных, которые использовались для обучения S посредством контролируемого обучения. Изменяя частоту (f) входного синусоидального сигнала до S (t, f), ученые могли генерировать углы суставов и крутящие моменты робота-гуманоида, соответствующие различным скоростям движения.
Результаты исследования
Чтобы продемонстрировать возможности разработанной системы управления (AI-CPG), ученые обучили агента-гуманоида выполнять задачу перемещения по прямой линии с разными скоростями на ровной поверхности. Для сравнения были использованы два алгоритма: PPO (от proximal policy optimization) и AMP (от adversarial motion priors). PPO — один из наиболее часто используемых методов DRL в робототехнике. Его преимуществом является обработка многомерных и непрерывных пространств состояний и действий со стабильной производительностью обучения. AMP — это новый алгоритм создания анимации и управления роботами, который сочетает в себе имитационное обучение, состязательное обучение и DRL. Это эффективный метод имитации естественного и реалистичного поведения на основе реальных данных о движении без необходимости искусственного проектирования функций вознаграждения.
Чтобы условия эксперимента при обучении были максимально схожими, количество эпох для каждого из трех алгоритмов составляло 3000, причем каждая эпоха длилась 1000 итераций. Число параллельно обученных актеров составило 8192, а используемые нейронные сети представляли собой MLP со скрытыми слоями размеров для всех трех алгоритмов. Два набора данных реального движения, использованные для обучения AMP, были идентичны тем, которые использовались для обучения AI-CPG.

Изображение №3
Для алгоритма PPO были установлены целевые скорости в функции вознаграждения равными 1.5, 2.0, 2.5, 3.0, 3.5 и 4.0 м/с. Алгоритм AMP изучает две разные скорости на основе используемых им данных о движении человека при ходьбе и беге. Для AI-CPG диапазон входной частоты генератора CPG составляет [0.8, 1.4] для обучения и [0.7, 1.4] для тестирования. Через каждые 100 эпох обучения нейронная сеть сохранялась в качестве контрольной точки. Каждый алгоритм обучался на пяти случайных начальных числах. Результат обучения показан на изображении выше.
Сравнивая CoT (от cost of transport) при разных средних скоростях на 3a, становится заметным тот факт, что агент, обученный с помощью AI-CPG, мог регулировать скорость своего движения, используя только один контроллер нейронной сети, даже для широкого диапазона скоростей. Кроме того, U-образная зависимость CoT-скорость при ходьбе и линейная зависимость CoT-скорость при беге очень похожи на таковые у человека.
Однако скорость движения робота, обученного с использованием алгоритма PPO, была ограничена структурой его функции вознаграждения. Алгоритм AMP чрезмерно ориентирован на то, чтобы движения робота были похожи на реальные, что затрудняет гибкую настройку скорости движения. Кроме того, по сравнению с алгоритмом AMP, алгоритмы PPO и AI-CPG оптимизировали энергоэффективность робота во время движения, следуя учету энергии в функции вознаграждения.
На 3b показано сравнение индекса симметрии робота на разных скоростях, а на 3e и 3f показана походка робота, движущегося в симуляторе. Было установлено, что, поскольку алгоритм PPO не ссылался на какие-либо реальные данные о движении во время тренировки, симметрия его походки была намного хуже, чем у AMP и AI-CPG. Эти ненормальные походки ограничивают применение метода PPO в реальных роботах.
Как показано на 3c, ученые проверили надежность контроллера походки, приложив определенную высокую случайную силу от -200 Н до 200 Н по всем осям к туловищу агента во время ходьбы. Период переложения внешней силы длился 0.1 секунды каждую секунду движения. В ходе 60-секундного теста было замечено, что для роботов, управляемых по одному и тому же алгоритму, состояние движения с низкой скоростью более нестабильно, чем состояние с высокой скоростью. Более того, у AI-CPG и AMP было меньше падений по сравнению с PPO в большинстве диапазонов скоростей. Это говорит о том, что походка, подобная человеческой, которую AMP и AI-CPG изучают на основе данных о движении человека, более устойчива к внешним воздействиям по сравнению с ненормальной походкой PPO.
На 3d ученые использовали «коэффициент фаз полета» для определения походки агента. Фаза полета — это фаза, в которой обе стопы не соприкасаются с землей в течение одного полного цикла ходьбы. В соответствии с соотношением фаз полета скорость движения, контролируемая AI-CPG, разделена на три периода черной пунктирной линией на 3a и 3d.
Область слева представляет собой устойчивую походку без фазы полета. Область в центре представляет собой переходную фазу походки, при которой фаза полета колеблется. Область справа представляет собой стабильную беговую походку, при которой соотношение фаз полета больше нуля и постоянно увеличивается с увеличением скорости. Результат подтверждает, что AI-CPG позволяет нейронной сети изучать различные походки, включая переходы от ходьбы к бегу.
На основании сравнения трех вышеперечисленных алгоритмов можно сделать вывод, что AI-CPG сочетает в себе преимущества имитационного обучения и DRL. Посредством формирования функции вознаграждения DRL помогает роботу научиться сохранять баланс и оптимизировать энергоэффективность. Походка, подобная человеческой, полученная на основе баз данных, позволяет AI-CPG лучше противостоять внешним воздействиям. Кроме того, механизм упреждающего управления в части CPG AI-CPG позволяет ему последовательно обрабатывать широкий диапазон скоростей движения и различных походок.

Изображение №4
Регулируя значение частоты (f) на контрольной точке, ученые добились плавного перехода от ходьбы к бегу. Связь между f и временем t составляет f (t) = 0.7 + 0.023t. Как показано на 4a, увеличение f приводит к постепенному уплотнению входного синусоидального сигнала в AI-CPG, что приводит к регулируемой динамической походке. Между тем, на 4b показаны изменения походки на разных стадиях. Когда и t, и f малы, робот движется медленно шагающей походкой. Соотношение фаз полета (Fr) и диаграмма походки на 4d подтверждают это наблюдение. По мере увеличения t и f скорость робота также увеличивалась, а соотношение фаз полета постепенно увеличивалось и колебалось, что указывает на переходную походку робота. Когда частота превышает 1.14 Гц, робот переходит к устойчивому бегу с дальнейшим увеличением t и f (4e).

Изображение №5
Далее ученые приступили к тестированию системы, использующей алгоритмы PPO, AI-CPG или AMP, в условиях неровной поверхности (перепады высоты в 10 см). На 5a показаны изменения траектории движения робота по мере увеличения обучающих итераций при разных целевых скоростях. Результаты показывают, что PPO и AI-CPG успешно управляли движением робота на неровной местности, тогда как AMP не смог справиться с этой задачей.
На ранних этапах обучения и PPO, и AI-CPG имели неупорядоченный вектор скорости (обозначенный темной стрелкой на изображении выше), который группировался вокруг начала координат, что делало агента неспособным эффективно двигаться. По мере увеличения количества обучающих итераций вектор скорости постепенно выравнивался с положительной осью X и смещался вправо, указывая на то, что агент научился двигаться в желаемом направлении. И наоборот, траектория и векторы скорости AMP всегда были неорганизованными и случайными.
На изображении 5b показано сравнение экспериментальных результатов PPO и AI-CPG. Сравнение показало, что AI-CPG превосходит PPO с точки зрения индекса симметрии, индекса баланса и CoT при двух разных скоростях движения. Важно отметить, что в случае AI-CPG используется одна и та же нейронная сеть как для ходьбы, так и для бега, тогда как для PPO требуется нейронная сеть для ходьбы и еще одна для бега. Кроме того, стандартное отклонение результатов AI-CPG было меньше, что указывает на более стабильный процесс обучения.

Изображение№6
Наконец, был протестирован переход от ходьбы к бегу на неровной местности, что является достаточно сложной задачей. AI-CPG, как и в случае с ровной поверхностью, успешно справился с данной задачей (график выше).
Принцип работы обучающей системы AI-CPG.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
В рассмотренном нами сегодня труде ученые описали новую систему управления движений человекоподобных роботов (AI-CPG), основанную на имитационном обучении и усиленных рефлекторных сетях.
На первый взгляд ходьба или даже бег кажутся весьма простыми для реализации процессами. Однако эта простота обусловлена биологическими процессами, которые позволяют нам в реальном времени адаптироваться к динамической окружающей среде. Но для двуногих роботов подобная адаптируемость является практически непосильной задачей. Суть в том, что роботу необходимо иметь базу данных потенциальных изменений рабочей среды, к которой он может обратиться в случае реализации одного из изменений. Нам это не нужно, ведь процесс адаптации происходит сам по себе, т. е. без обязательной привязки к предыдущему опыту.
Авторы исследования решили использовать глубокое обучение с подкреплением (DRL от deep reinforcement learning), которое расширяет традиционное обучение с подкреплением, используя глубокие нейронные сети для решения более сложных задач и обучения непосредственно на основе необработанных сенсорных данных. Однако DRL обладает весьма существенным недостатком, а именно огромными вычислительными затратами.
Другой подход, называемый имитационным обучением, использует данные о движения реальных людей. Этот метод отлично справляется в ситуациях стабильных условий (например, полностью ровная поверхность), но становится малоэффективным, когда условия меняются (например, перепады высоты на поверхности).
Ученые смогли преодолеть ограничения вышеописанных методов, объединив их в единое целое. В результате робот был обучен не только ходить и бегать, но и подстраиваться под динамически меняющуюся среду и плавно переходить от ходьбы к бегу.
Авторы разработки уверены, что их труд является значимым шагом к реализации генеративного искусственного интеллекта для управления роботами с потенциальным применением в различных отраслях.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?